De verkiezingen naderen en de peilingen volgen elkaar in hoog tempo op. Het LISS-Panel van de Universiteit Tilburg komt elke dag met een nieuwe peiling. Peil van Maurice de Hond doet het elke week en de Politieke Barometer elke twee weken. De Stemming van GfK de peilingen van I&O Research en Kantar TNS hebben een lagere frequentie. Al die peilingen beogen hetzelfde te meten en dat is het stemgedrag. Dus zouden al die peilingen dezelfde prognoses moeten opleveren (als ze op hetzelfde moment worden uitgevoerd). Dat blijkt niet zo te zijn. Zo komt de vraag op of je door al die bomen het bos nog wel kunt zien.
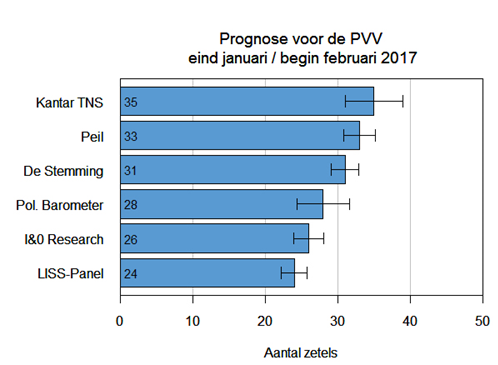
De grafiek hieronder laat de prognoses voor de PVV zien waarmee de peilingen eind januari / begin februari 2017 kwamen. Er blijken nogal wat verschillen tussen die peilingen te zitten. De prognoses voor de PVV lopen uiteen van 24 zetels (door het LISS-Panel) tot 35 (door Kantar TNS). Dat is een verschil maar liefst 11 zetels. Hoe kan dit? In deze bijdrage wordt een poging gedaan hiervoor een verklaring te vinden. Het is ook een pleidooi voor betere onderzoeksdocumentatie.
Aanzienlijke verschillen
Het is niet verwonderlijk dat de prognoses verschillen. Alle peilingen maken gebruik van steekproeven. Elke steekproef is anders en daarom is ook elke prognose anders. Als een steekproef netjes is getrokken, dan kan de maximale omvang van deze ‘ruis’ worden berekend. Dat is de onzekerheidsmarge. De grafiek toont de onzekerheidsmarges in de vorm van foutbalken aan het einde van de staven. De foutbalken van bijvoorbeeld Peil en De Stemming overlappen elkaar. Daarom kan niet de conclusie worden getrokken dat de uitkomsten van de peilingen verschillen. Dat is bijvoorbeeld wel het geval bij het LISS-Panel en Kantar TNS. De foutbalken overlappen elkaar helemaal niet. Ze zijn duidelijk gescheiden. Er is dus een essentieel verschil tussen beide peilingen dat niet kan worden verklaard door de ruis van de steekproef. Een blik op de grafiek moet dan ook leiden tot de conclusie dat er behoorlijke ‘echte’ verschillen tussen de peilingen zitten.
Deelnemers panel
Al deze peilingen maken gebruik van een web-panel. Dat is een groep mensen die heeft aangegeven wel regelmatig vragenlijsten te willen invullen. De steekproeftheorie adviseert om een dergelijk panel altijd te vullen door het trekken van een aselecte steekproef. Loting bepaalt dus wie er in de steekproef komt en wie niet. Deze aanpak garandeert dat de uitkomsten valide zijn, dus dat de peiling meet wat hij moet meten. Andere manieren om een steekproef te trekken kunnen vertekeningen veroorzaken. Van de zes steekproeven is er maar één netjes geloot. Dat is de steekproef van het LISS-Panel. Die steekproef is door het Centraal Bureau voor de Statistiek geloot uit de bevolkingsadministratie (Basisregistratie Personen). Het panel van Peil is niet geloot. Rekrutering is gebaseerd op zelfselectie. Iedereen die zichzelf spontaan aanmeldt, mag meedoen. Zelfselectie kan de representativiteit van het panel ernstig aantasten. De andere peilers zijn minder duidelijk over de opbouw van hun panels. Het lijkt erop dat ze deels gebruik maken van zelfselectie, deels van respondenten uit ander onderzoek en deels van de sneeuwbaltechniek (leden van het panel nodigen familie en vrienden uit ook mee te doen). Vanuit het perspectief van de representativiteit van de steekproef lijkt het LISS-Panel de beste peiling te zijn.
Selectieprocedure stemmers
Om de politieke voorkeur in kaart te brengen, moet eerst aan de respondenten worden gevraagd of ze wel gaan stemmen. Voor het schatten van de stemmenpercentages voor de verschillende partijen is de politieke voorkeur van de niet-stemmers immers niet interessant. De peilingen vragen op verschillende manieren of men gaat stemmen. Bij het LISS-Panel moeten de respondenten met een percentage tussen de 0% en 100% aangeven wat de kans is dat ze gaan stemmen.
Bij I&O Research en Kantar TNS kunnen de respondenten bij de stemvraag kiezen uit vijf opties: “Zeker wel”, “Waarschijnlijk wel”, “Waarschijnlijk niet”, “Zeker niet” en “Weet niet/wil niet zeggen” Bij de Politieke Barometer zijn er maar vier opties. De optie “Weet niet/wil niet zeggen” is verdwenen. Iemand die het echt nog niet weet, kan dat dus niet meer aangeven. Uit de antwoorden op deze vraag moeten dan de respondenten geselecteerd die echt gaan stemmen. Zijn dat alleen de respondent die aangeven zeker wel te gaan stemmen? Of moeten ook zij die waarschijnlijk wel gaan stemmen worden meegenomen. I&O Research gebruikte eerst beide categorieën, maar heeft in februari 2017 besloten alleen nog maar “zeker wel” te gebruiken.
De peilers vragen aan de stemmers op welke partij ze gaan stemmen. Vaak weten ze dat nog niet en twijfelen ze nog over hun keuze. Die onzekerheid kan op allerlei manieren worden gemeten. Bij het LISS-Panel geven de stemmers percentages aan partijen van hun mogelijke keuze. Een dergelijk percentage geeft de kans weer dat de desbetreffende partij wordt gekozen. Bij Kantar TNS krijgt elke stemmer 10 stemmen die hij/zij kan verdelen over de partijen. Bij De Stemming mogen de stemmers vijf stemmen verdelen. En dan zijn er ook nog peilingen waarbij je gewoon één stem aan een partij geeft. Het is niet duidelijk welke aanpak het meeste valide antwoord oplevert.
Non-respons
Hoe goed een peiling ook is opgezet, de peiler krijgt altijd te maken met non-respons. Die non-respons kan in de eerste plaats optreden bij de opbouw van een panel. Er zijn immers heel wat mensen die niet zo enthousiast zijn over het regelmatig invullen van vragenlijsten. Daarom willen ze geen lid worden van het panel. Maar ook in elke peiling opnieuw die uit het panel wordt geselecteerd, treedt non-respons op. Naarmate de non-respons hoger is, zal dat tot ernstiger afwijkingen kunnen leiden. Helaas vermelden veel peilers het non-responspercentage niet. Kantar TNS meldt dat de respons in hun peilingen rond de 70% ligt. En GfK geeft aan dat bij De Stemming iets meer dan de helft van de respondenten de vragenlijst ingevuld. Dat is dus niet erg hoog gegeven het feit dat in hun panel mensen zitten die hebben aangegeven te willen meedoen aan peilingen.
Weegvariabelen
Door de wijze van werven voor het web-panel en door de optredende non-respons wordt de representativiteit van het panel aangetast. Daarom is het altijd noodzakelijk de uitkomsten te corrigeren. Daarvoor wordt een weging uitgevoerd. Daarmee wordt het panel representatief gemaakt met betrekking tot variabelen als geslacht, leeftijd, regio, opleidingsniveau en stemgedrag bij voorgaande verkiezingen. De hoop is dan dat de peiling zo ook representatief wordt met betrekking tot stemgedrag bij de komende verkiezingen. Iedere peiler kiest voor zijn eigen weegtechniek. Helaas is het zo dat een andere weging tot andere uitkomsten kan leiden. Stemgedrag bij de vorige verkiezingen lijkt een belangrijke weegvariabele te zijn. Maar dan moet die variabele wel goed worden gemeten. Als nu wordt gevraagd wat men vier jaar geleden heeft gestemd, dan zal dat heel wat onjuiste antwoorden opleveren. Men weet het niet meer of men wil het niet zeggen. Dus is het beter om die vraag vlak na de vorige verkiezingen te stellen, en de antwoorden te bewaren voor toekomstige peilingen. In februari 2017 is daarom I&O Research gestopt met het gebruik van deze variabele in de weging. Het vanaf 2014 vragen naar stemgedrag in 2012 leidde tot teveel fouten.
Verbetering betrouwbaarheid
Uit het voorgaande zal duidelijk zijn geworden dat er veel verschillen zijn tussen de peilingen. Dat zijn alleen nog maar verschillen die zijn te halen uit de spaarzame documentatie van de peilingen. Misschien zijn er nog wel meer. Die verschillen zijn van invloed op de uitkomsten. Dat is verwarrend voor de media en het grote publiek. Steeds weer zal de vraag opkomen welke peiling goed is en welke niet. Hoe het kaf van het koren te scheiden?
Een eerste stap om meer duidelijkheid te krijgen is het verbeteren van de onderzoeksdocumentatie. Daarmee wordt helder wat alle overeenkomsten en verschillen zijn. Verder zouden allerlei interessante analyses kunnen worden uitgevoerd. Een voorbeeld van zo’n analyse is het herhalen van het NOPVO-onderzoek uit 2006. Daarin werden 19 web-panels met elkaar vergeleken op basis van een aselecte steekproef uit elk panel. Zoiets zou weer kunnen worden gedaan met de web-panels van de huidige peilers. Een andere vraag die opdoemt is wat de uitkomsten zouden zijn als de peilers elkaars vragenlijsten zouden gebruiken. Ook is het belangrijk om de verschillende wegingen grondig te analyseren en zo te komen tot de meest effectieve weging. Kortom, er is nog genoeg werk aan de winkel.